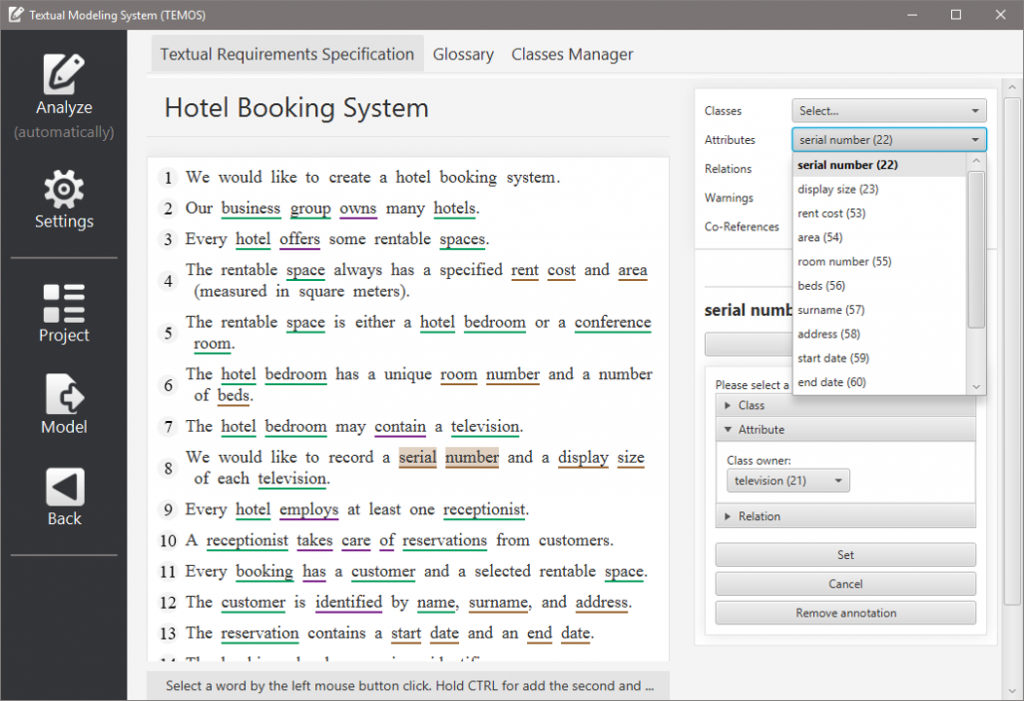
Specifikace v podobě textového dokumentu se využívá k vyjasnění požadavků na softwarový systém mezi zákazníkem, uživatelem, doménovým expertem a analytikem. Specifikace požadavků se běžně píší v přirozeném jazyce, kterému rozumí všechny zúčastněné strany. Přirozený jazyk je nicméně díky své obecnosti náchylný k řadě nepřesností jako je víceznačnost, nekonzistence či neúplnost.
S využitím metod gramatické inspekce tvoříme větné vzory, které jsou v textu schopné najít potřebné informace (disciplína zvaná Text Mining). Náš nástroj TEMOS (TExtual MOdelling System) pomocí těchto vzorů, on-line slovníků (jako je například Wordnik) a sémantických sítí (např. ConceptNet či BabelNet) poskytuje následující funkce: detekce souvětí podezřelých z víceznačnosti či neúplnosti, automatická tvorba a údržba slovníku pojmů, generování fragmentu statického UML diagramu tříd, export modelu ve formátech XMI, ECORE či DOT.
Šenkýř, D., Suchánek, M., Kroha, P., Mannaert, H., & Pergl, R. (2022). Expanding Normalized Systems from textual domain descriptions using TEMOS. Journal of Intelligent Information Systems. https://doi.org/10.1007/s10844-022-00706-8
Šenkýř, D., & Kroha, P. (2020). Patterns for Checking Incompleteness of Scenarios in Textual Requirements Specification: Proceedings of the 15th International Conference on Evaluation of Novel Approaches to Software Engineering, 289–296. https://doi.org/10.5220/0009344202890296
Šenkýř, D. (2019). SHACL Shapes Generation from Textual Documents. In R. Pergl, E. Babkin, R. Lock, P. Malyzhenkov, & V. Merunka (Eds.), Enterprise and Organizational Modeling and Simulation (Vol. 366, pp. 121–130). Springer International Publishing. https://doi.org/10.1007/978-3-030-35646-0_9
Šenkýř, D., & Kroha, P. (2019). Patterns of Ambiguity in Textual Requirements Specification. In Á. Rocha, H. Adeli, L. P. Reis, & S. Costanzo (Eds.), New Knowledge in Information Systems and Technologies (Vol. 930, pp. 886–895). Springer International Publishing. https://doi.org/10.1007/978-3-030-16181-1_83
Šenkýř, D., & Kroha, P. (2019). Problem of Incompleteness in Textual Requirements Specification. Proceedings of the 14th International Conference on Software Technologies, 323–330. https://doi.org/10.5220/0007978003230330
Šenkýř, D., & Kroha, P. (2018). Patterns in Textual Requirements Specification. Proceedings of the 13th International Conference on Software Technologies, 231–238. https://doi.org/10.5220/0006827302310238